Nội dung bài viết
© 2025 AI VIET NAM. All rights reserved.
Tác giả: Tue-Thu Van-Dinh (AIO2024), Hoang-Duy Tran (AIO2024), Quang-Vinh Dinh (Lecturer), Phuc-Thinh Nguyen (AIO2024, CM)
Keywords: học deep learning online, UNet, Computer Vision
Image Segmentation (phân vùng ảnh) là một nhiệm vụ quan trọng trong lĩnh vực thị giác máy tính, trong đó một bức ảnh được chia thành nhiều vùng khác nhau với mục tiêu đơn giản hóa hoặc thay đổi biểu diễn của bức ảnh thành một dạng có ý nghĩa hơn để dễ dàng phân tích. Image Segmentation thường được sử dụng để xác định vị trí các đối tượng hoặc đường biên, hay nói cách khác, đây là quá trình gán nhãn cho từng pixel trong ảnh, sao cho các pixel thuộc cùng một đối tượng hoặc khu vực sẽ được nhóm lại với nhau.
Image Segmentation và Object Detection (phát hiện đối tượng) đều có chung mục tiêu là xác định các vùng chứa đối tượng và gán nhãn cho chúng; tuy nhiên, Image Segmentation yêu cầu độ chính xác cao hơn. Khác với Object Detection, nơi đối tượng được định vị thông qua các hộp giới hạn (bounding boxes), Image Segmentation yêu cầu nhãn dự báo phải chính xác đến từng pixel trong ảnh. Điều này giúp chúng ta hiểu rõ hơn về nội dung bức ảnh, không chỉ dừng lại ở việc xác định vị trí các vật thể mà còn mô tả được hình dạng của chúng, cũng như gán từng pixel vào đúng vật thể tương ứng.

Image Segmentation được chia làm ba loại:
Semantic Segmentation: Gán nhãn cho từng pixel trong ảnh và nhóm các pixel có cùng ngữ nghĩa vào một lớp cụ thể. Quá trình này phân đoạn các vùng ảnh theo từng lớp khác nhau mà không phân biệt giữa các đối tượng riêng lẻ thuộc cùng một lớp.
Instance Segmentation: Phân đoạn các vùng ảnh chi tiết đến từng đối tượng trong mỗi lớp.
Panoptic segmentation: Kết hợp giữa Semantic Segmentation và Instance Segmentation, trong đó mỗi đối tượng được phân đoạn với ranh giới rõ ràng, đồng thời danh tính và ý nghĩa của từng đối tượng trong ảnh được dự đoán chính xác.

Image Segmentation thường được sử dụng trong nhiều ứng dụng thực tiễn như:
Y học: Phân đoạn các tế bào, mô hoặc cơ quan trong ảnh chụp X-quang, CT, hoặc MRI.
Xử lý ảnh vệ tinh: Phân loại vùng đất, rừng, sông ngòi từ các bức ảnh vệ tinh.
Xe tự hành: Nhận diện đường, xe cộ, người đi bộ và các vật thể khác để hỗ trợ định vị và dẫn đường.

Có hai phương pháp chính để thực hiện Image Segmentation:
Phương pháp truyền thống - dựa trên các thuật toán như:
Phân ngưỡng (Thresholding) để chia điểm ảnh thành các lớp dựa trên cường độ.
Phân cụm (Clustering) như K-means để nhóm các điểm ảnh có đặc trưng tương đồng.
Phân đoạn theo vùng (Region-based Segmentation) dựa vào sự tương đồng về màu sắc hoặc kết cấu.
Phân đoạn theo cạnh (Edge-based Segmentation) để xác định ranh giới của các đối tượng trong hình ảnh.
Phương pháp hiện đại:
Sử dụng mạng nơ-ron tích chập (CNN) để học và trích xuất các đặc trưng trực tiếp từ dữ liệu, được huấn luyện để tự động nhận diện những đặc trưng quan trọng trong ảnh, thay vì dựa vào các hàm tùy chỉnh như trong các phương pháp truyền thống.
Các mạng nơ-ron dùng để phân đoạn thường áp dụng cấu trúc encoder-decoder. Encoder sẽ trích xuất các đặc trưng của ảnh qua các bộ lọc ngày càng hẹp và sâu hơn. Nếu encoder được huấn luyện sẵn trên các nhiệm vụ như nhận diện khuôn mặt hay nhận dạng ảnh, nó sẽ tận dụng kiến thức đã học để hỗ trợ phân đoạn (học chuyển giao). Sau đó, decoder sẽ mở rộng kết quả của encoder qua nhiều lớp để tạo ra mặt nạ phân đoạn có độ phân giải pixel giống hệt ảnh đầu vào.
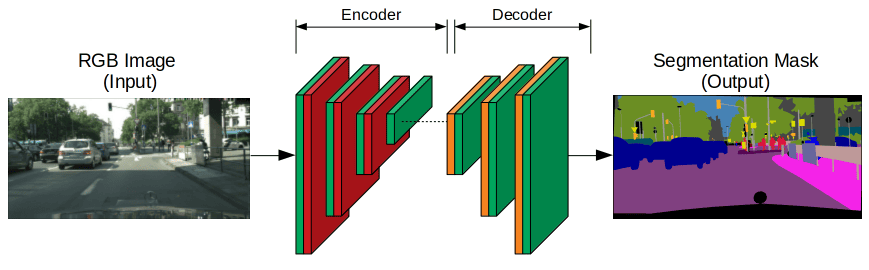
Trong bối cảnh các bài toán phức tạp, các phương pháp học sâu đã trở thành lựa chọn hàng đầu nhờ khả năng xử lý chi tiết và duy trì thông tin không gian. Đặc biệt, kiến trúc mạng U-Net nổi bật với thiết kế đối xứng độc đáo và khả năng phân đoạn chính xác ở cấp độ pixel, giúp bảo tồn các chi tiết nhỏ trong ảnh. Do đó, U-Net đã trở thành giải pháp lý tưởng cho những bài toán đòi hỏi độ chi tiết cao, nơi việc duy trì thông tin không gian là vô cùng quan trọng.
Trong tài liệu này, chúng ta sẽ khám phá kiến trúc mạng U-Net và cách áp dụng nó để giải quyết bài toán về Image Segmentation.
U-Net là một mạng nơ-ron tích chập được thiết kế ban đầu cho phân đoạn ảnh y sinh. Kiến trúc của U-Net bao gồm 2 phần chính là encoder và decoder đối xứng nhau với hình dạng giống chữ U.
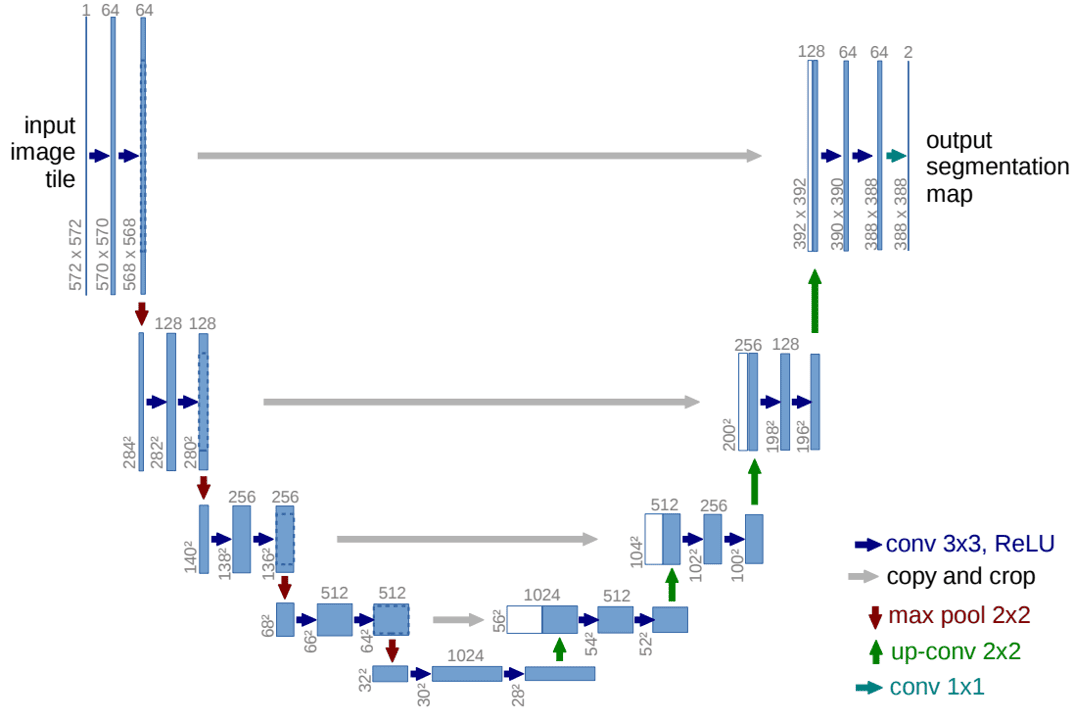
Hình 5 trên mô tả kiến trúc mạng U-Net, trong đó:
Mỗi hình chữ nhật màu xanh biểu thị một multi-channel feature map.
Số lượng channels được ghi chú ở phía trên hình chữ nhật.
Kích thước x-y được cung cấp ở góc dưới bên trái của hình chữ nhật.
Các hình chữ nhật màu trắng đại diện cho các feature maps được sao chép.
Các mũi tên biểu thị các operations khác nhau:
| Mũi tên | Ý nghĩa |
|---|---|
 | Conv layer 3x3, ReLU |
 | Skip Connections (có crop) |
 | Max Pooling 2x2 |
 | Transposed Convolution |
 | Conv layer 1x1 |
U-Net lần đầu tiên giới thiệu skip connections trong Deep Learning như một giải pháp hiệu quả để khắc phục mất mát thông tin trong quá trình downsampling, thường gặp trong các khối mã hóa (encoder) của kiến trúc encoder-decoder. Skip connections là các kết nối trực tiếp từ encoder đến decoder mà không cần đi qua bottleneck, giúp giảm thiểu mất mát dữ liệu do các phương pháp aggressive pooling và downsampling gây ra.
Việc sử dụng skip connections giúp khắc phục vấn đề mất thông tin ở spatial dimension. Nếu chỉ dựa vào feature map từ bottleneck để xây dựng lại feature map có độ phân giải cao, nhiều chi tiết về vị trí pixel sẽ bị mất. Nhờ các kết nối này, thông tin từ phần encoder được truyền trực tiếp sang decoder, hỗ trợ việc tái tạo vị trí pixel chính xác hơn.
Convolution là một phép toán cơ bản trong xử lý dữ liệu, đặc biệt là trong mạng nơ-ron tích chập (CNN). Phép toán này sử dụng một kernel (bộ lọc) trượt qua dữ liệu đầu vào, tính tích chập để tạo ra bản đồ đặc trưng (feature map). Kết quả thường có kích thước nhỏ hơn, giúp trích xuất các đặc trưng cục bộ quan trọng như cạnh, góc hoặc mẫu hình.
Trong khi Convolution giảm kích thước không gian của dữ liệu, Transposed Convolution (hay còn gọi là Deconvolution) thực hiện ngược lại: nó mở rộng dữ liệu đầu vào. Đây là một kỹ thuật phổ biến trong các bài toán như Image Generation hoặc Image Segmentation, nơi cần khôi phục dữ liệu về kích thước ban đầu hoặc tạo dữ liệu có độ phân giải cao hơn.
Trong Convolution tiêu chuẩn, kích thước không gian của feature map được giảm bằng cách áp dụng kernel có kích thước cố định, kết hợp với stride và padding. Ngược lại, Transposed Convolution thực hiện chức năng mở rộng kích thước không gian của feature map bằng cách áp dụng kernel lên đầu vào, đồng thời điều chỉnh kích thước output thông qua stride và padding. Có thể hiểu, Transposed Convolution là quá trình ngược của Convolution thông thường, trong đó mỗi feature được ánh xạ thành các pixel của ảnh, thay vì ánh xạ các pixel thành feature như trong Convolution tiêu chuẩn (hình 6 dưới đây minh họa sự khác biệt giữa hai quá trình này).
So với các phương pháp upsampling truyền thống như Nearest Neighbors, Bi-Linear Interpolation hay Max-Unpooling, Transposed Convolution vượt trội hơn nhờ khả năng học các tham số từ dữ liệu, giúp khôi phục thông tin không gian một cách chi tiết và chính xác hơn.

Quy trình thực hiện Transposed Convolution:
Nhân tích chập và xử lý dịch chuyển stride:
Mỗi phần tử trong input feature map được nhân với kernel, sau đó kết quả được đặt vào vị trí tương ứng trên output feature map.
Với stride = s, kết quả sẽ dịch chuyển s pixel sau mỗi lần tính toán, và stride lớn sẽ làm tăng kích thước của output.
Xử lý chồng chéo (overlap): Khi kích thước stride nhỏ hơn kích thước kernel, các vùng trên ma trận kết quả sẽ bị chồng lên nhau. Trong trường hợp này, các giá trị tại các vị trí chồng chéo sẽ được cộng lại để tạo thành giá trị cuối cùng tại vị trí đó.

Áp dụng padding:
Padding được thêm vào để đảm bảo kích thước output phù hợp.
Với padding = p, tiến hành loại bỏ p hàng và cột ở 4 cạnh (trên, dưới, trái, phải) của kết quả đầu ra. Lưu ý:
Khi padding = (p, q): bỏ đi p hàng đầu tiên và cuối cùng (trên, dưới); q cột đầu tiên và cuối cùng (trái, phải) của output.
Khi padding = p: đây là cách viết rút gọn, tương đương với padding = (p, p).
Công thức tổng quát để xác định kích thước output:
Trong đó:
m x n: kích thước input.
h x k: kích thước kernel.
s x t: kích thước stride.
p x q: kích thước padding.
Ví dụ minh họa:
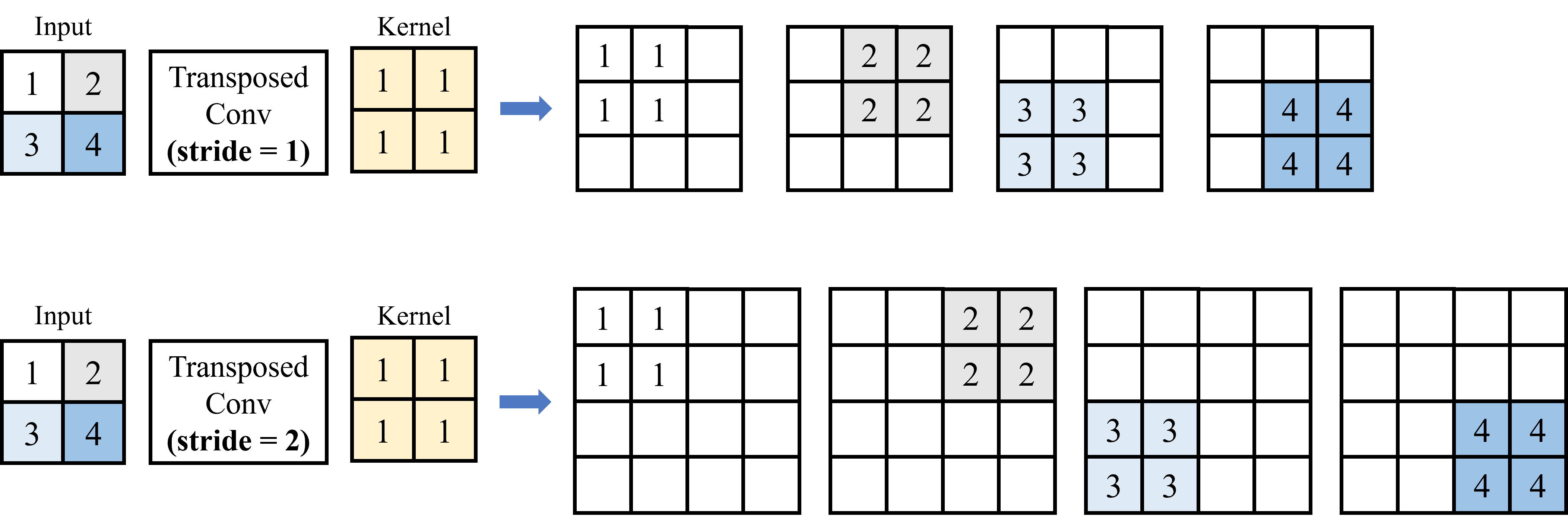
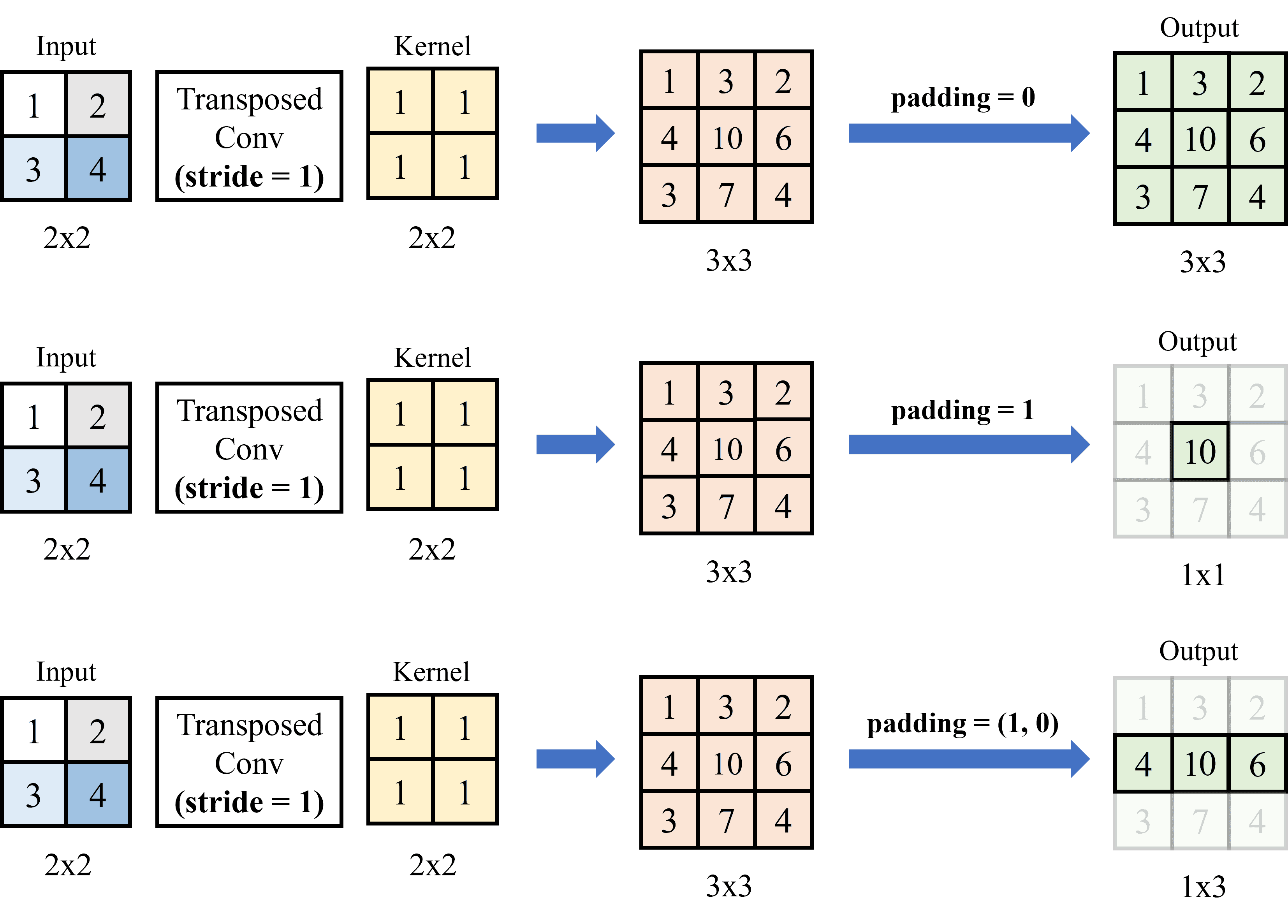
Để hiểu rõ hơn các bước tính toán trong quá trình Transposed Convolution, chúng ta sẽ cùng thực hiện hai ví dụ với input và kernel được mô tả trong Hình 10.
Input: Một encoded feature map kích thước 2x2.
Kernel có kích thước 2x2.
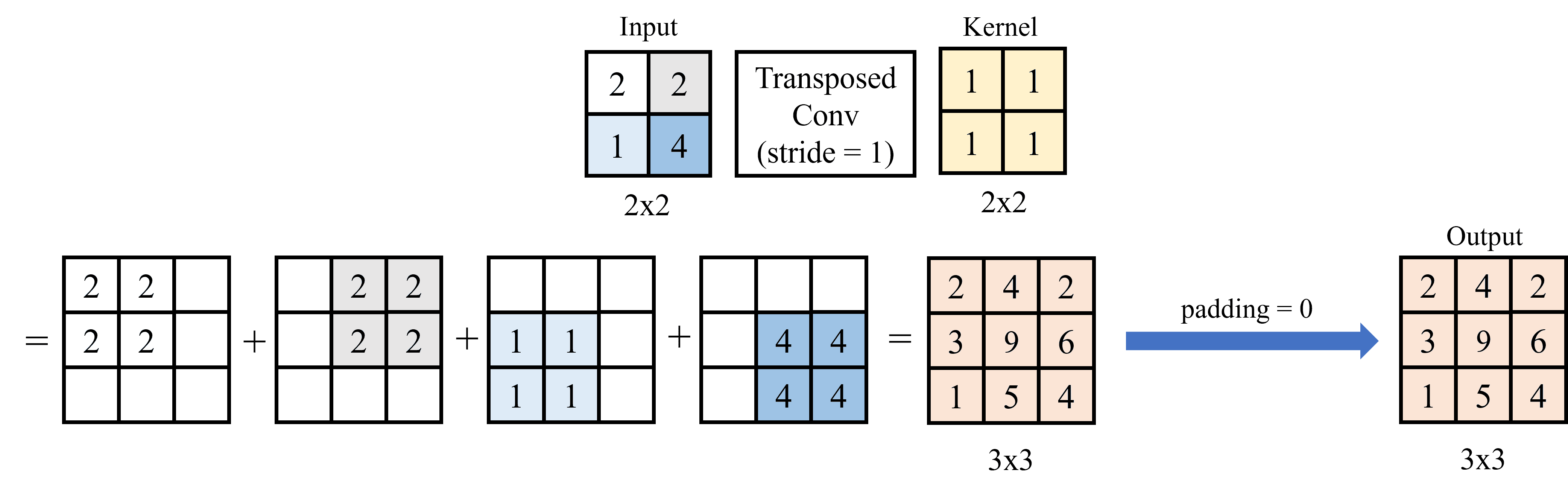
Ví dụ 1: Với stride = 1 và padding = 0.
Đầu tiên, lấy từng pixel input nhân với kernel (nhân với từng phần tử). Với stride = 1, di chuyển kết quả của mỗi lần nhân pixel với kernel sang 1 pixel.
Sau khi thực hiện nhân tích chập, vì stride có kích thước nhỏ hơn kernel nên cần cộng các giá trị chồng chéo (overlap) lại với nhau. Trong trường hợp này, vì padding = 0 nên không loại bỏ hàng hay cột nào ở output. Hình 11 dưới đây minh họa cho quá trình tính Transposed Convolution cho ví dụ đầu tiên:
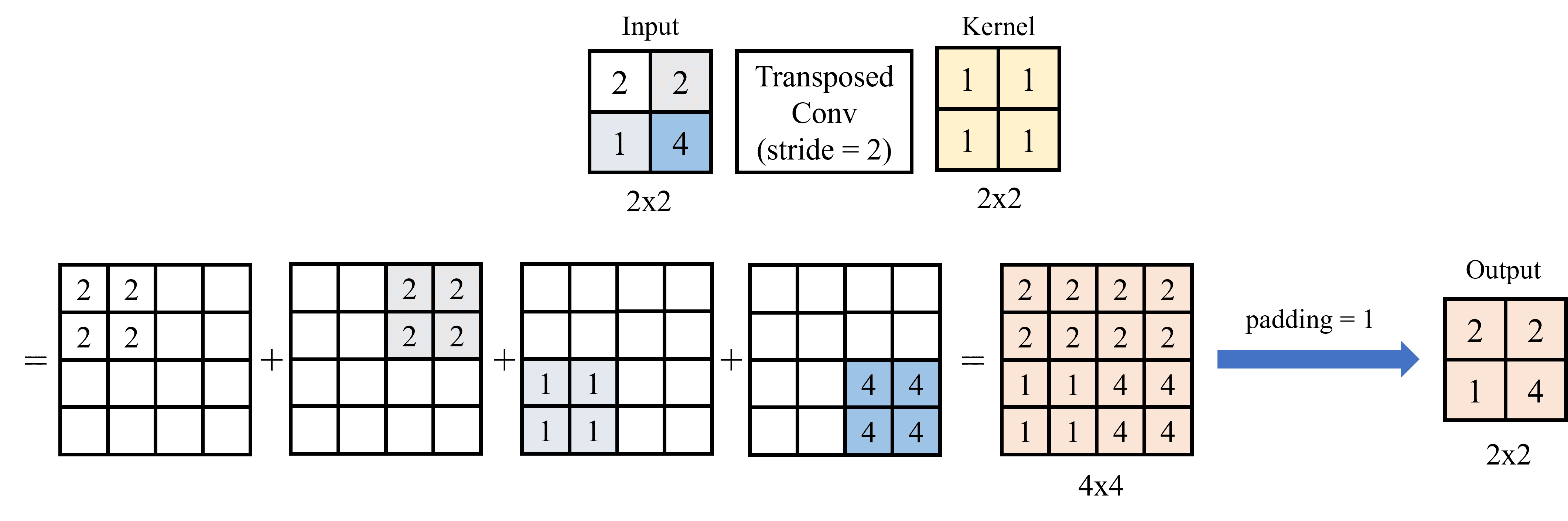
Ví dụ 2: Với stride = 2 và padding = 1.
Đầu tiên, lấy từng pixel input nhân với kernel (nhân với từng phần tử). Với stride = 2, di chuyển kết quả của mỗi lần nhân pixel với kernel sang 2 pixel.
Sau khi thực hiện nhân chập, các giá trị không bị overlap vì kích trước của stride không nhỏ hơn kích thước kernel.
Với padding = 1, tiến hành loại bỏ 1 hàng và cột ở 4 cạnh (trên, dưới, trái, phải) của kết quả đầu ra. Hình 12 dưới đây minh họa trình tính Transposed Convolution cho ví dụ 2:
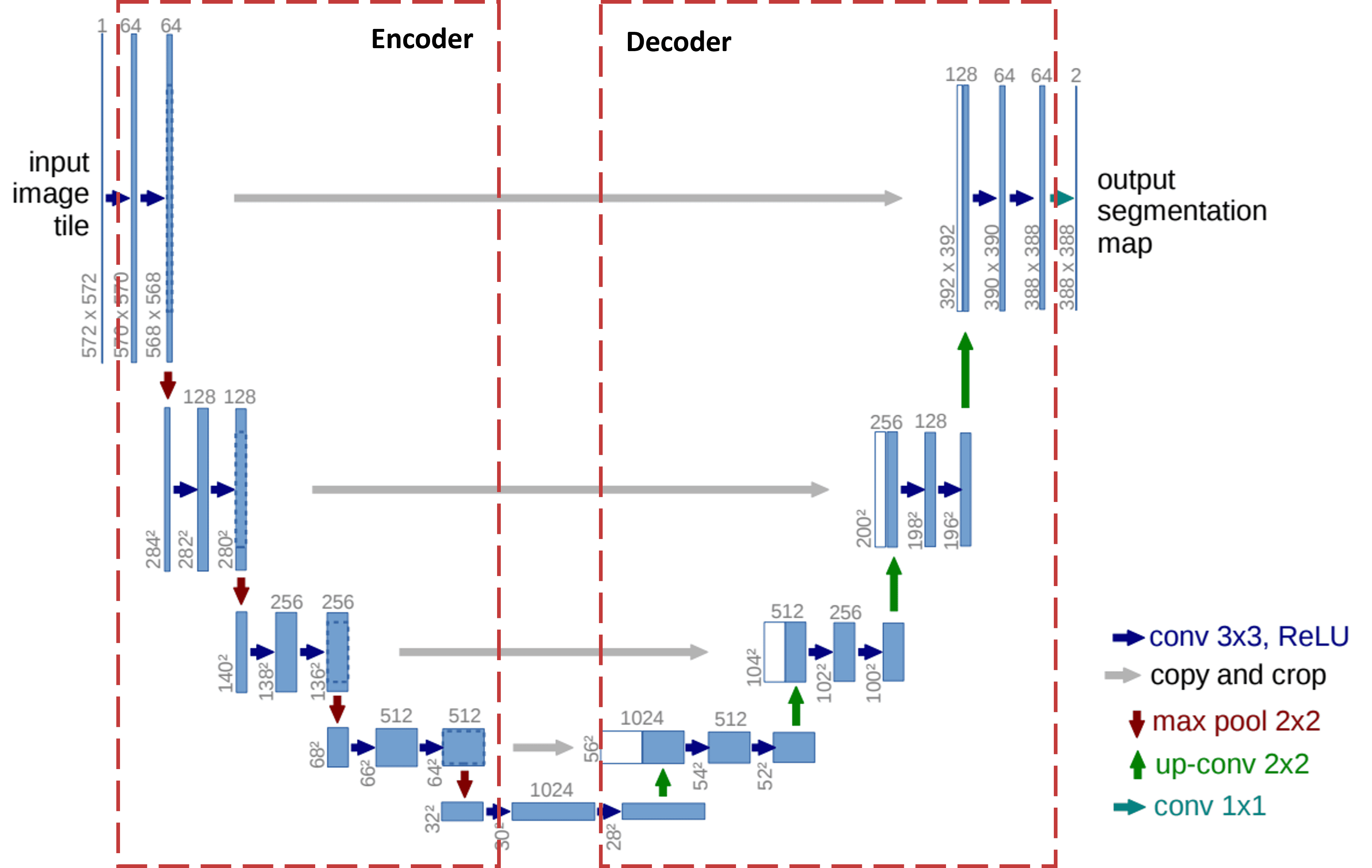
Dựa vào hình 13, phần encoder bao gồm các lớp Conv và MaxPooling thông thường. Khi đi từ trên xuống dưới, kích thước width x height giảm, trong khi depth tăng lên (depth của output mỗi lớp được ghi ở trên đỉnh của hình chữ nhật, còn kích thước width và height được ghi dọc theo hình chữ nhật).
Encoder được thiết kế với mục tiêu trích xuất các đặc trưng quan trọng từ ảnh đầu vào thông qua các lớp convolution và pooling. Quá trình này không chỉ giúp nhận diện các đặc trưng quan trọng mà còn giảm dần kích thước không gian của ảnh, đồng thời giữ lại những thông tin đặc trưng cần thiết cho các bước xử lý tiếp theo trong mô hình.
Phần này được thiết kế ngược lại với encoder vì nó làm tăng kích thước width x height, đồng thời giảm depth. Để thực hiện điều này, ta sử dụng Transposed Convolution. Tại mỗi giai đoạn của decoder, layer đối xứng tương ứng của encoder sẽ được crop và concatenate lại. Từ hình 13, ta có thể thấy rõ cách thức hoạt động của decoder, với các bước thực hiện tăng dần kích thước không gian và tái tạo lại thông tin đã bị nén trong encoder.
Ngoài ra, kiến trúc U-Net không sử dụng lớp fully connected (FC) ở phần cuối, điều này tạo ra sự khác biệt so với các mô hình Deep Learning truyền thống. Trong các mô hình end-to-end thông thường, lớp FC sẽ kết nối các đặc trưng đã được trích xuất qua các lớp convolution để đưa ra kết quả dự đoán cuối cùng. Tuy nhiên, U-Net, việc kết nối các đặc trưng và tạo ra kết quả dự đoán được thực hiện thông qua phần up-sampling ở nửa thứ hai của "chữ U" (decoder).
Đây là bài toán phân lớp cho các pixels nên loss function sẽ bằng tổng cross entropy của các pixels trong ảnh.
Trong phần thực hành, chúng ta sẽ sử dụng kiến trúc U-Net để giải quyết bài toán Image Segmentation trên các bộ dataset cụ thể. Quá trình này bao gồm việc huấn luyện mô hình và đánh giá hiệu suất trên dữ liệu thực tế.
Đối với bài toán này, chúng ta sẽ xây dựng một mô hình Segmentation nhằm phân đoạn hình ảnh thú cưng (chó/mèo) từ tập dữ liệu Oxford-IIIT Pet Dataset. Mục tiêu của bài toán là tạo ra một mặt nạ (mask) phân đoạn, trong đó mỗi pixel được gán vào một trong ba lớp: Background (nền), Pet (vùng chứa thú cưng), Contour(đường viền phân tách giữa thú cưng và nền).
Bài toán segmentation này không chỉ giúp xác định rõ ràng vùng thú cưng trong ảnh mà còn là nền tảng để giải quyết các bài toán phức tạp hơn, như tách nền tự động, phân tích hình dáng, hoặc nhận diện giống loài.
Đầu tiên, chúng ta sẽ import các thư viện cần thiết để xử lý dữ liệu và xây dụng mô hình.
import copy import numpy as np import torch import torch.nn as nn import torch.nn.functional as F import matplotlib.pyplot as plt
Oxford-IIIT Pet Dataset là một tập dữ liệu phổ biến, được thiết kế dành cho các bài toán Image Classification và Image Segmentation. Bộ dữ liệu này do nhóm nghiên cứu tại Đại học Oxford phát triển, cung cấp cả nhãn phân loại chó mèo và mặt nạ phân đoạn chi tiết.

Trong phần này, chúng ta sẽ xử lý dữ liệu từ Oxford-IIIT Pet Dataset bằng cách áp dụng các phép biến đổi (transforms) cho ảnh và mặt nạ phân đoạn. Ảnh sẽ được chuẩn hóa, resize về kích thước đồng nhất và chuyển đổi thành tensor, trong khi mặt nạ phân đoạn được xử lý để đảm bảo các giá trị pixel phù hợp với định dạng yêu cầu của mô hình.
Dữ liệu đã được chia sẵn thành hai phần: tập huấn luyện (trainval) và tập kiểm tra (test) để sử dụng cho quá trình huấn luyện và đánh giá mô hình một cách hiệu quả.
from torchvision import transforms from torchvision.datasets import OxfordIIITPet from torch.utils.data import DataLoader img_size = (128, 128) num_classes = 3 transform = transforms.Compose([ transforms.Resize(img_size), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) ]) def target_transform(target): img = transforms.Resize(img_size)(target) img = transforms.functional.pil_to_tensor(img).squeeze_() img = img - 1 img = img.to(torch.long) return img train_set = OxfordIIITPet(root="pets_data", split="trainval", target_types="segmentation", transform=transform, target_transform=target_transform, download=True) test_set = OxfordIIITPet(root="pets_data", split="test", target_types="segmentation", transform=transform, target_transform=target_transform, download=True) batch_size = 64 train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=6) test_loader = DataLoader(test_set, batch_size=batch_size, num_workers=6)
Quá trình de-normalize được thực hiện để đưa dữ liệu về phạm vi giá trị ban đầu, giúp hiển thị ảnh rõ ràng hơn để có thể kiểm tra và đánh giá mô hình.
def de_normalize(img, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)): result = img * std + mean result = np.clip(result, 0.0, 1.0) return result
Ở phần này, chúng ta sẽ bắt đầu xây dựng kiến trúc U-Net để giải quyết bài toán phân đoạn ảnh.
Đầu tiên, ta thiết kế khối Convolutional (ConvBlock), đây là thành phần cốt lõi của U-Net. Khối này được sử dụng để trích xuất đặc trưng từ ảnh đầu vào thông qua các lớp tích chập. Sau đó, ConvBlock sẽ được sử dụng để xây dựng các thành phần chính trong U-Net như Encoder và Decoder.
class ConvBlock(nn.Module): def __init__(self, in_channels, out_channels) -> None: super().__init__() self.conv_block = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), ) def forward(self, x): x = self.conv_block(x) return x
class Encoder(nn.Module): def __init__(self, in_channels, out_channels) -> None: super().__init__() self.encoder = nn.Sequential( nn.MaxPool2d(2), ConvBlock(in_channels, out_channels) ) def forward(self, x): x = self.encoder(x) return x
class Decoder(nn.Module): def __init__(self, in_channels, out_channels) -> None: super().__init__() self.conv_trans = nn.ConvTranspose2d(in_channels, out_channels, \ kernel_size=4, stride=2, padding=1) self.conv_block = ConvBlock(in_channels, out_channels) def forward(self, x1, x2): x1 = self.conv_trans(x1) x = torch.cat([x2, x1], dim=1) x = self.conv_block(x) return x
class UNet(nn.Module): def __init__(self, n_channels, n_classes) -> None: super().__init__() self.n_channels = n_channels self.n_classes = n_classes self.in_conv = ConvBlock(n_channels, 64) self.enc_1 = Encoder(64, 128) self.enc_2 = Encoder(128, 256) self.enc_3 = Encoder(256, 512) self.enc_4 = Encoder(512, 1024) self.dec_1 = Decoder(1024, 512) self.dec_2 = Decoder(512, 256) self.dec_3 = Decoder(256, 128) self.dec_4 = Decoder(128, 64) self.out_conv = nn.Conv2d(64, n_classes, kernel_size=1) def forward(self, x): x1 = self.in_conv(x) x2 = self.enc_1(x1) x3 = self.enc_2(x2) x4 = self.enc_3(x3) x5 = self.enc_4(x4) x = self.dec_1(x5, x4) x = self.dec_2(x, x3) x = self.dec_3(x, x2) x = self.dec_4(x, x1) x = self.out_conv(x) return x
@torch.inference_mode() def display_prediction(model, image, target): model.eval() img = image[None,...].to(device) output = model(img) pred = torch.argmax(output, axis=1) plt.figure(figsize=(10, 5)) plt.subplot(1,3,1) plt.axis('off') plt.title("Input Image") plt.imshow(de_normalize(image.numpy().transpose(1,2,0))) plt.subplot(1,3,2) plt.axis('off') plt.title("Prediction") plt.imshow(pred.cpu().squeeze()) plt.subplot(1,3,3) plt.axis('off') plt.title("Ground Truth") plt.imshow(target) plt.show()
def evaluate(model, test_loader, criterion): model.eval() test_loss = 0.0 with torch.no_grad(): for inputs, labels in test_loader: inputs, labels = inputs.to(device), labels.to(device) outputs = model(inputs) loss = criterion(outputs, labels) test_loss += loss.item() test_loss = test_loss / len(test_loader) return test_loss
device = "cuda" if torch.cuda.is_available() else "cpu" max_epoch = 30 LR = 0.001 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=LR)
Trong phần này, chúng ta sẽ thực hiện huấn luyện mô hình U-Net để giải quyết bài toán phân đoạn ảnh. Sau mỗi epoch, kết quả đánh giá sẽ được in ra màn hình cùng với hình ảnh dự đoán và mặt nạ thực tế để dễ dàng theo dõi và trực quan hóa hiệu suất của mô hình.
test_index = 80 display_image = test_set[test_index][0] display_target = test_set[test_index][1] train_losses = [] test_losses = [] best_loss = float('inf') best_model_wts = copy.deepcopy(model.state_dict()) model.to(device) for epoch in range(max_epoch): model.train() running_loss = 0.0 for inputs, targets in train_loader: inputs, targets = inputs.to(device), targets.to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, targets) running_loss += loss.item() loss.backward() optimizer.step() epoch_loss = running_loss / len(train_loader) test_loss = evaluate(model, test_loader, criterion) if test_loss < best_loss: best_loss = test_loss best_model_wts = copy.deepcopy(model.state_dict()) print(f"Epoch [{epoch + 1}/{max_epoch}], \ Trainning loss: {epoch_loss:.4f}, Test Loss: {test_loss:.4f}") print(f"Test image_{test_index} after epoch {epoch+1}: ") display_prediction(model, display_image, display_target) train_losses.append(epoch_loss) test_losses.append(test_loss)
Phần này là bước cuối cùng trong quy trình, mô hình thực hiện dự đoán 10 ảnh đầu tiên trên tập kiểm tra, giúp đánh giá hiệu suất mô hình và xác nhận rằng mô hình hoạt động tốt nhất với trọng số đã lưu.
model.load_state_dict(best_model_wts) n_test_points = 10 for i in range(n_test_points): img, gt = test_set[i] display_prediction(model, img, gt)
Sau khi huấn luyện xong, kết quả đạt được của mô hình như sau:

Trong bài toán này, chúng ta sẽ xây dựng một mô hình Segmentation nhằm phân đoạn hình ảnh nội soi từ tập dữ liệu Kvasir-SEG. Mục tiêu chính của bài toán là tạo ra một mặt nạ (mask) phân đoạn, trong đó mỗi pixel được gán vào một trong hai lớp: Background (nền) hoặc Polyp (vùng tổn thương có hình dáng giống một khối u).
import os import cv2 import copy import torch import random import numpy as np from PIL import Image from glob import glob import torch.nn as nn import torch.nn.functional from torchvision import transforms from matplotlib import pyplot as plt from torch.utils.data import Dataset, DataLoader from sklearn.model_selection import train_test_split
Kvasir-SEG là một bộ dữ liệu chuẩn trong lĩnh vực phân đoạn y tế, đặc biệt được sử dụng cho các nhiệm vụ phân đoạn đa dạng như phát hiện và phân đoạn tổn thương trong nội soi tiêu hóa. Bộ dữ liệu này do Simula Research Laboratory phát triển và công bố, nhằm hỗ trợ nghiên cứu về phân tích hình ảnh nội soi.
!gdown 1vmtDOK6BQMfjoZZVZcn8mOPfpwsGWlym !unzip Kvasir-SEG.zip
ROOT_PATH = '/content/Kvasir-SEG/Kvasir-SEG' images_path = os.path.join(ROOT_PATH, 'images') masks_path = os.path.join(ROOT_PATH, 'masks')
Ở phần này chúng ta sẽ xử lý dữ liệu nhằm chuẩn bị đầu vào phù hợp, trong đó có việc chuyển đổi ảnh về ảnh xám (gray scale), với ảnh nội soi trong bộ dữ liệu Kvasir-SEG thường không yêu cầu thông tin màu sắc đầy đủ (RGB) để phân đoạn vùng tổn thương. Do đó, việc chuyển đổi sang ảnh xám là một cách tối ưu hóa tài nguyên, đồng thời giữ lại thông tin cần thiết phục vụ cho mô hình.
img_size = (128, 128) image_transform = transforms.Compose([ transforms.Resize(img_size), transforms.Grayscale(num_output_channels=1), transforms.ToTensor(), transforms.Normalize(mean=[0.485], std=[0.229]) ]) def mask_transform(mask): mask = transforms.Resize(img_size, interpolation=Image.NEAREST)(mask) mask = transforms.functional.pil_to_tensor(mask).squeeze(0) mask = mask / 255.0 mask = torch.round(mask).long() return mask
Mặc dù bộ dữ liệu Kvasir-SEG cung cấp hình ảnh và nhãn chất lượng cao, số lượng mẫu trong tập dữ liệu này vẫn còn hạn chế (chỉ khoảng 1.000 ảnh). Điều này dễ dẫn đến overfitting, đặc biệt khi sử dụng các mô hình học sâu với số lượng tham số lớn.
Vì vậy, ta sẽ áp dụng các phương pháp data augmentation để củng cố lượng dữ liệu cho mô hình. Cụ thể:
Elastic Transform (Biến dạng đàn hồi): Áp dụng biến dạng không gian mềm mại để mô phỏng sự thay đổi tự nhiên trong hình ảnh nội soi, giúp mô hình nhận diện đặc trưng tốt hơn khi hình ảnh bị biến dạng.
Horizontal Flip (Lật ngang): Lật ảnh và mask theo chiều ngang, tăng khả năng nhận diện đặc trưng đối xứng, hữu ích với các tổn thương có tính đối xứng trái-phải.
Vertical Flip (Lật dọc): Lật ảnh và mask theo chiều dọc, bổ sung sự đa dạng, giúp mô hình thích nghi với góc nhìn khác nhau.
Combined Flip (Kết hợp lật và biến dạng đàn hồi): Kết hợp Elastic Transform, Horizontal Flip, và Vertical Flip để tạo các biến thể dữ liệu phong phú nhất, tăng khả năng học đặc trưng và cải thiện tổng quát hóa của mô hình.
def elastic_transform(image, mask, alpha_affine=10): random_state = np.random.RandomState(None) shape = image.size[::-1] # (H, W) center_square = np.float32(shape) // 2 square_size = min(shape) // 3 pts1 = np.float32([center_square + square_size, [center_square[0] + square_size, center_square[1] - square_size], center_square - square_size]) pts2 = pts1 + \ random_state.uniform(-alpha_affine, alpha_affine, size=pts1.shape).astype(np.float32) M = cv2.getAffineTransform(pts1, pts2) image = cv2.warpAffine(np.array(image), M, shape[::-1], borderMode=cv2.BORDER_REFLECT_101) mask = cv2.warpAffine(np.array(mask), M, shape[::-1], borderMode=cv2.BORDER_REFLECT_101) return Image.fromarray(image), Image.fromarray(mask) def hflip_transform(image, mask): return image.transpose(Image.FLIP_LEFT_RIGHT), mask.transpose(Image.FLIP_LEFT_RIGHT) def vflip_transform(image, mask): return image.transpose(Image.FLIP_TOP_BOTTOM), mask.transpose(Image.FLIP_TOP_BOTTOM) def flip_transform(image, mask): return image.transpose(Image.FLIP_LEFT_RIGHT).transpose(Image.FLIP_TOP_BOTTOM), \ mask.transpose(Image.FLIP_LEFT_RIGHT).transpose(Image.FLIP_TOP_BOTTOM)
class KvasirDatasetAugmented(Dataset): def __init__(self, images_path, masks_path, transform=None, \ target_transform=None, augmentations=None): self.images_path = sorted(os.listdir(images_path)) self.masks_path = sorted(os.listdir(masks_path)) self.images_dir = images_path self.masks_dir = masks_path self.transform = transform self.target_transform = target_transform self.augmentations = augmentations if augmentations else [] self.data = self._generate_augmented_data() def _generate_augmented_data(self): augmented_data = [] for img_file, mask_file in zip(self.images_path, self.masks_path): img_path = os.path.join(self.images_dir, img_file) mask_path = os.path.join(self.masks_dir, mask_file) image = Image.open(img_path).convert("RGB") mask = Image.open(mask_path).convert("L") augmented_data.append((image, mask)) for aug_func in self.augmentations: aug_image, aug_mask = aug_func(image, mask) augmented_data.append((aug_image, aug_mask)) return augmented_data def __len__(self): return len(self.data) def __getitem__(self, idx): image, mask = self.data[idx] if self.transform: image = self.transform(image) if self.target_transform: mask = self.target_transform(mask) return image, mask
augmentations = [elastic_transform, hflip_transform, vflip_transform, flip_transform] dataset = KvasirDatasetAugmented(images_path, masks_path, \ transform=image_transform, target_transform=mask_transform, augmentations=augmentations)
train_size = int(0.7 * len(dataset)) val_size = int(0.15 * len(dataset)) test_size = len(dataset) - train_size - val_size train_dataset, val_dataset, test_dataset = torch.utils.data.random_split(dataset, \ [train_size, val_size, test_size])
batch_size = 64 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=2) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
Ở phần này chúng ta sẽ tiến hành xây dựng mô hình U-Net để Segmentation cho bộ dữ liệu Kvasir-SEG, nhưng vì cấu trúc mô hình không thay đổi nên chúng ta sẽ tái sử dụng cấu trúc mô hình U-Net từ bài toán trước.
device = "cuda" if torch.cuda.is_available() else "cpu" model = UNet(n_channels=1, n_classes=2).to(device) criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
best_loss = float('inf') best_model_wts = copy.deepcopy(model.state_dict()) for epoch in range(30): model.train() train_loss = 0.0 for inputs, targets in train_loader: inputs, targets = inputs.to(device), targets.to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, targets) loss.backward() optimizer.step() train_loss += loss.item() train_loss = train_loss / len(train_loader) val_loss = evaluate(model, val_loader, criterion) if val_loss < best_loss: best_loss = val_loss best_model_wts = copy.deepcopy(model.state_dict()) print(f"Epoch {epoch + 1}, Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}")
def display_prediction(model, image, ground_truth, device): image = image.unsqueeze(0).to(device) with torch.no_grad(): prediction = model(image) prediction = torch.argmax(prediction, dim=1).squeeze(0).cpu().numpy() image_np = image.squeeze(0).permute(1, 2, 0).cpu().numpy() ground_truth_np = ground_truth.cpu().numpy() fig, axs = plt.subplots(1, 3, figsize=(15, 5)) axs[0].imshow(image_np, cmap='gray') axs[0].set_title("Input Image") axs[1].imshow(ground_truth_np, cmap='gray') axs[1].set_title("Ground Truth") axs[2].imshow(prediction, cmap='gray') axs[2].set_title("Prediction") for ax in axs: ax.axis("off") plt.show()
Mô hình được sử dụng để dự đoán 10 ảnh đầu tiên từ tập kiểm tra nhằm đánh giá hiệu suất tổng thể của mô hình và đảm bảo rằng nó đạt được kết quả tốt nhất với trọng số đã lưu.
model.load_state_dict(best_model_wts) n_test_points = 10 model.eval() test_samples = [test_dataset[i] for i in range(n_test_points)] for i in range(n_test_points): img, gt = test_samples[i] display_prediction(model, img, gt, device)
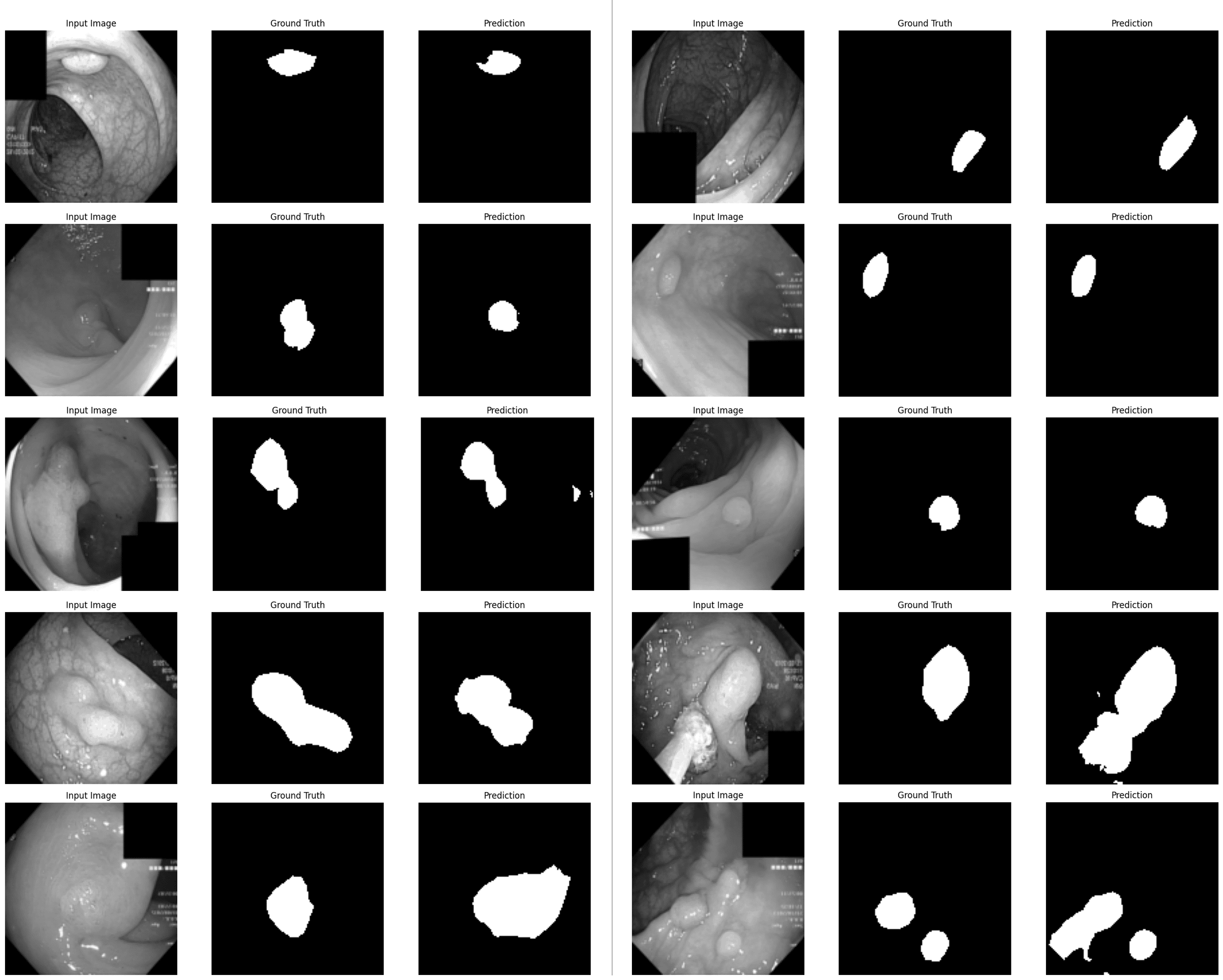
- Hết -
Bài viết liên quan
Chuyển giao tri thức (Knowledge Distillation) với mạng CNN
tháng 7 2025
Bài viết này giới thiệu phương pháp chuyển giao tri thức (Knowledge Distillation) bằng thư viện PyTorch ở bài toán phân loại hình ảnh. Mô hình được sử dụng sẽ là ResNet18 cho student và DenseNet169 cho teacher.
Step-by-Step: Vision Transformer
tháng 6 2025
Tài liệu này minh họa chi tiết từng bước hoạt động của mô hình Vision Transformer, hay còn gọi là ViT. Chúng ta sẽ phân tích chi tiết cơ chế hoạt động và thảo luận từng bước thực hiện của mô hình này.